
布隆过滤器
是什么
用来判断”某样东西一定不存在,或者可能存在“
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少;
但是缺点是其返回的结果是概率性的,而不是确切的。
原理
布隆过滤器(Bloom Filter)本质上是由长度为 m 的位向量或bit数组,最初所有的值均设置为 0,如下图所示。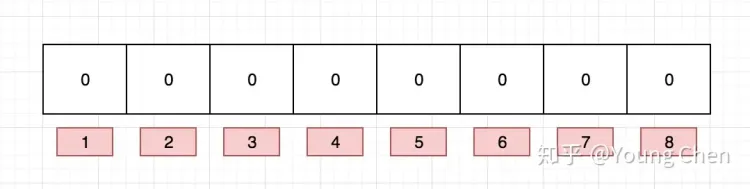
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为: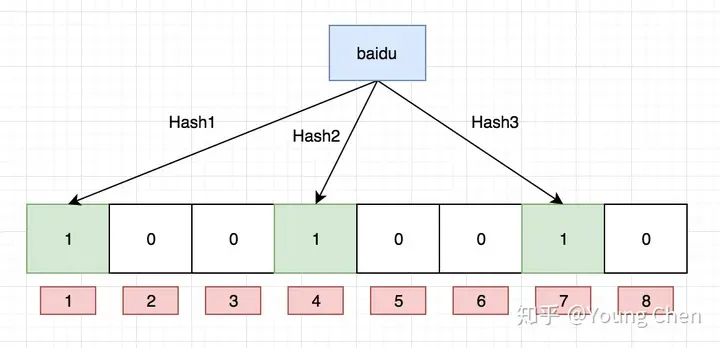
现在再计算一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为: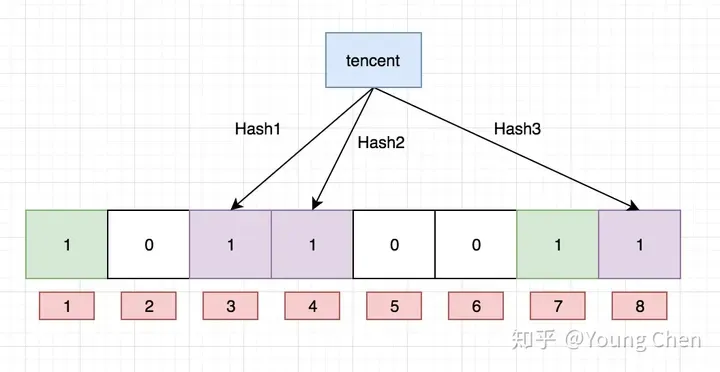
值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。
而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
使用场景/主要作用
在实际工作中,布隆过滤器常见的应用场景如下:
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
- Google Chrome 使用布隆过滤器识别恶意 URL;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。
除了上述的应用场景之外,布隆过滤器还有一个应用场景就是解决缓存穿透的问题。所谓的缓存穿透就是服务调用方每次都是查询不在缓存中的数据,这样每次服务调用都会到数据库中进行查询,如果这类请求比较多的话,就会导致数据库压力增大,这样缓存就失去了意义。
利用布隆过滤器我们可以预先把数据查询的主键,比如用户 ID 或文章 ID 缓存到过滤器中。当根据 ID 进行数据查询的时候,我们先判断该 ID 是否存在,若存在的话,则进行下一步处理。若不存在的话,直接返回,这样就不会触发后续的数据库查询。需要注意的是缓存穿透不能完全解决,我们只能将其控制在一个可以容忍的范围内。
- 利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
- 然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
QA
为什么只能判断可能存在
因为bitMap中存的是目标值的多个哈希值,而多个哈希值之间会覆盖,因此不同目标值的哈希值可能会组成新的不存在的值,也可能是已存在的值,因此是可能存在。同理,如果找不到目标值对应的所有哈希值,则一定不存在。
一致性哈希
背景
传统取模算法在分布式集群的扩容缩容场景有较强的局限性。
为什么需要一致性哈希算法?
假设有这么一种场景:我们有三台缓存服务器分别为:node0、node1、node2,有3000万个缓存数据需要存储在这三台服务器组成的集群中,希望可以将这些数据均匀的缓存到三台机器上,你会想到什么方案呢?
我们可能首先想到的方案是:取模算法hash(key)%N,即:对缓存数据的key进行hash运算后取模,N是机器的数量;运算后的结果映射对应集群中的节点。
首先对key进行hash计算后的结果对3取模,得到的结果一定是0、1或者2;然后映射对应的服务器node0 node1、node2,最后直接找对应的服务器存取数据即可。
通过取模算法将每个数据请求都均匀的分散到了三个不同的服务器节点上,看起来很完美!
但是,在分布式集群系统的负载均衡实现上,这种模型在集群扩容和收缩时却有一定的局限性:
因为在生产环境中根据业务量的大小,调整服务器数量是常有的事,而服务器数量N发生变化后hash(key)%N计算的结果也会随之变化!导致整个集群的缓存数据必须重新计算调整,进而导致大量缓存在同一时间失效,造成缓存的雪崩,最终导致整个缓存系统的不可用。
这是不能接受的。为了解决优化上述情况,一致性哈希算法应运而生。
什么是一致性哈希
一致性哈希是一种特殊的哈希算法,目的是解决分布式系统的数据分区问题:当分布式集群移除或者添加一个服务器时,必须尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。
一致性哈希主要用来降低节点上下线的过程中带来的数据迁移成本,同时节点数量的变化与分片原则对于应用系统来说是无感的,使上层应用更专注于领域内逻辑的编写,使得整个系统架构能够动态伸缩,更加灵活方便。
原理
对2^32取模,具有良好的单调性。即,只要key值固定,那么模也是固定的
当增加或者删除一台服务器时,受影响的数据仅仅是新添加或删除的服务器到其环空间中前一台的服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他都不会受到影响
一个设计良好的分布式系统应该具有良好的单调性,即服务器的添加与移除不会造成大量的哈希重定位,而一致性哈希恰好可以解决这个问题 。
其实,一致性哈希算法本质上也是一种取模算法。只不过前面介绍的取模算法是按服务器数量取模,而一致性哈希算法是对固定值2^32取模,这就使得一致性算法具备良好的单调性:不管集群中有多少个节点,只要key值固定,那所请求的服务器节点也同样是固定的。其算法的工作原理如下:
- 一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间的取值范围为0~2^32-1;
- 计算各服务器节点的哈希值,并映射到哈希环上;
- 将服务发来的数据请求使用哈希算法算出对应的哈希值;
- 将计算的哈希值映射到哈希环上,同时沿圆环顺时针方向查找,遇到的第一台服务器就是所对应的处理请求服务器。
- 当增加或者删除一台服务器时,受影响的数据仅仅是新添加或删除的服务器到其环空间中前一台的服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他都不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性 。
数据倾斜与虚拟节点
前面说了一致性哈希算法的原理以及扩容缩容的问题。但是,由于哈希计算的随机性,导致一致性哈希算法存在一个致命问题:数据倾斜。也就是说大多数访问请求都会集中少量几个节点的情况。特别是节点太少情况下,容易因为节点分布不均匀造成数据访问的冷热不均。这就失去了集群和负载均衡的意义。
如何解决数据倾斜?
为了解决数据倾斜的问题,一致性哈希算法引入了虚拟节点机制,即对每一个物理服务节点映射多个虚拟节点,将这些虚拟节点计算哈希值并映射到哈希环上,当请求找到某个虚拟节点后,将被重新映射到具体的物理节点。
虚拟节点越多,哈希环上的节点就越多,数据分布就越均匀,从而避免了数据倾斜的问题。
说起来可能比较复杂,一句话概括起来就是:原有的节点、数据定位的哈希算法不变,只是多了一步虚拟节点到实际节点的映射。具体如下图所示:![image.png]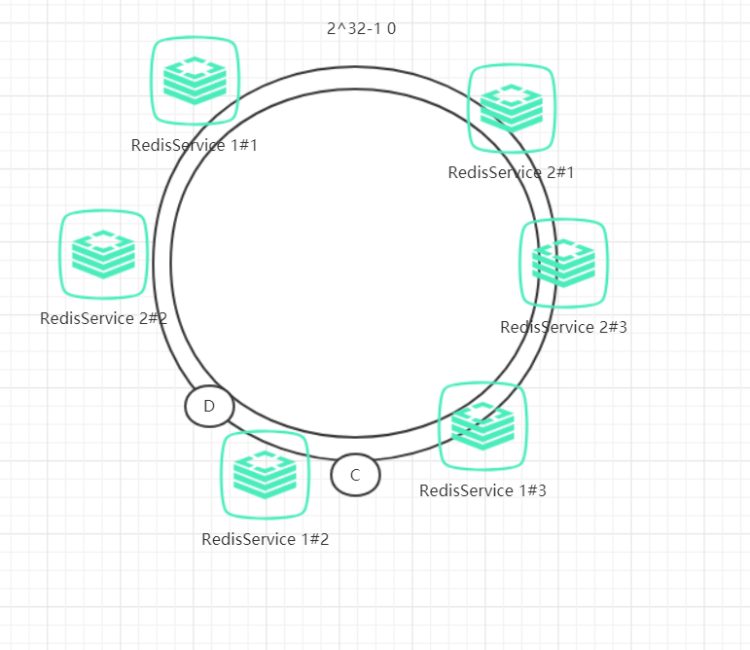
我们可以在服务器ip或主机名的后面增加编号来实现,将全部的虚拟节点加入到哈希环中,增加了节点后,数据在哈希环上的分布就相对均匀了。当有访问请求寻址到2#3这个虚拟节点时,将被重新映射到物理节点2#1。
使用场景/主要作用
一致性哈希算法是分布式系统中的重要算法。主要是在负载均衡、缓存数据分区等场景使用。
一致性哈希应该是实现负载均衡的首选算法,它的实现比较灵活,既可以在客户端实现,也可以在中间件上实现,比如日常使用较多的缓存中间件memcached 使用的路由算法用的就是一致性哈希算法。
此外,其它的应用场景还有很多:
- RPC框架Dubbo用来选择服务提供者
- 分布式关系数据库分库分表:数据与节点的映射关系
- LVS负载均衡调度器